Co-reporter:Lei Liu, Maria Tsompana, Yong Wang, Dingfeng Wu, Lixin Zhu, and Ruixin Zhu
Journal of Chemical Information and Modeling 2016 Volume 56(Issue 9) pp:1615-1621
Publication Date(Web):August 10, 2016
DOI:10.1021/acs.jcim.6b00397
Drug discovery and development is a costly and time-consuming process with a high risk for failure resulting primarily from a drug’s associated clinical safety and efficacy potential. Identifying and eliminating inapt candidate drugs as early as possible is an effective way for reducing unnecessary costs, but limited analytical tools are currently available for this purpose. Recent growth in the area of toxicogenomics and pharmacogenomics has provided with a vast amount of drug expression microarray data. Web servers such as CMap and LTMap have used this information to evaluate drug toxicity and mechanisms of action independently; however, their wider applicability has been limited by the lack of a combinatorial drug-safety type of analysis. Using available genome-wide drug transcriptional expression profiles, we developed the first web server for combinatorial evaluation of toxicity and efficacy of candidate drugs named “Connection Map for Compounds” (CMC). Using CMC, researchers can initially compare their query drug gene signatures with prebuilt gene profiles generated from two large-scale toxicogenomics databases, and subsequently perform a drug efficacy analysis for identification of known mechanisms of drug action or generation of new predictions. CMC provides a novel approach for drug repositioning and early evaluation in drug discovery with its unique combination of toxicity and efficacy analyses, expansibility of data and algorithms, and customization of reference gene profiles. CMC can be freely accessed at http://cadd.tongji.edu.cn/webserver/CMCbp.jsp.
Co-reporter:Dingfeng Wu, Tianyi Qiu, Qingchen Zhang, Hong Kang, Shaohua Yuan, Lixin Zhu, and Ruixin Zhu
Chemical Research in Toxicology 2015 Volume 28(Issue 3) pp:419
Publication Date(Web):January 27, 2015
DOI:10.1021/tx5003782
Proton pump inhibitors (PPIs) are extensively used for the treatment of gastric acid-related disorders. PPIs appear to be well tolerated and almost have no short-term side effects. However, the clinical adverse reactions of long-term PPI usage are increasingly reported in recent years. So far, there is no study that elucidates the side effect mechanisms of PPIs comprehensively and systematically. In this study, a well-defined small molecule perturbed microarray data set of 344 compounds and 1695 samples was analyzed. With this high-throughput data set, a new index (Identity, I) was designed to identify PPI-specific differentially expressed genes. Results indicated that (1) up-regulated genes, such as RETSAT, CYP1A1, CYP1A2, and UGT, enhanced vitamin A’s metabolism processes in the cellular retinol metabolism pathway; and that (2) down-regulated genes, such as C1QA, C1QC, C4BPA, C4BPB, CFI, and SERPING1, enriched in the complement and coagulation cascades pathway. In addition, strong association was observed between these PPI-specific differentially expressed genes and the reported side effects of PPIs by the gene–disease association network analysis. One potential toxicity mechanism of PPIs as suggested from this systematic PPI-specific gene expression analysis is that PPIs are enriched in acidic organelles where they are activated and inhibit V-ATPases and acid hydrolases, and consequently block the pathways of antigen presentation, the synthesis and secretion of cytokines, and complement component proteins and coagulation factors. The strategies developed in this work could be extended to studies on other drugs.
Co-reporter:Chuan Tian;Lixin Zhu;Dan Yu;Zhiwei Cao;Tingguo Kang
Chemical Biology & Drug Design 2014 Volume 83( Issue 5) pp:610-621
Publication Date(Web):
DOI:10.1111/cbdd.12274
PPIs are mainly metabolized by CYP2C19. It has a stereoselectivity effect on R- and S-isomers of PPIs according to previous studies. However, no study has been reported to elucidate the binding mechanism at the atomic level based on the CYP2C19 crystal structure. Recently, the advent of the first crystal structure of CYP2C19 allowed us to take in silico approaches including MD simulation, MM/GBSA calculation, energy decomposition, and alanine scanning to explore the stereoselectivity of CYP2C19 on R- and S-isomers of PPIs. The key residues responsible for the selective binding for R- and S-isomers of omeprazole, lansoprazole, and pantoprazole are disclosed by free energy and alanine scanning analysis. Structural analysis showed that chiral isomers of PPIs alter their conformations to have strong binding affinities with CYP2C19. Furthermore, a theoretical pharmacophore model of PPIs was obtained with the importance of pharmacophore feature being weighted, basing on our results. Our results are valuable for designing and synthesizing new generation of PPIs in the future.
Co-reporter:Chao Ma;Kailin Tang;Qi Liu;Zhiwei Cao
Chemical Biology & Drug Design 2013 Volume 81( Issue 6) pp:775-783
Publication Date(Web):
DOI:10.1111/cbdd.12124
Berberine is an isoquinoline alkaloid that has drawn extensive attention because it possesses various biological activities. Several mechanisms have been proposed to interpret the anticancer activity of berberine. However, these explanations are mostly based on its downstream-regulated genes or proteins; information on the direct target proteins that mediate the antiproliferative action of berberine remains unclear. In this study, a computational pipeline based on a ligand–protein inverse docking program and mining of the ‘Connectivity MAP’ data was adopted to explore the potential target proteins for berberine. The results showed that four proteins, that is calmodulin, cytochrome P450 3A4, sex hormone-binding globulin, and carbonic anhydrase II, were suggested to be the potential targets of berberine. The anticalmodulin property of berberine was demonstrated with an in vitro phosphodiesterase activity assay. Flow cytometric analysis found that G1 cell cycle arrest induced by berberine in Bel7402 cells was enhanced by cotreatment with calmodulin inhibitors. Western blotting results indicated that berberine treatment decreased phosphorylation of calmodulin kinase II and blocked subsequent MEK1 activation as well as p27 protein degradation. These results suggested that calmodulin might play crucial roles in berberine-induced cell cycle arrest in cancer cells.
Co-reporter:Tianli Dai;Qi Liu;Jun Gao;Zhiwei Cao
BMC Bioinformatics 2011 Volume 12( Issue 14 Supplement) pp:
Publication Date(Web):2011 December
DOI:10.1186/1471-2105-12-S14-S9
Prediction of protein-ligand binding sites is an important issue for protein function annotation and structure-based drug design. Nowadays, although many computational methods for ligand-binding prediction have been developed, there is still a demanding to improve the prediction accuracy and efficiency. In addition, most of these methods are purely geometry-based, if the prediction methods improvement could be succeeded by integrating physicochemical or sequence properties of protein-ligand binding, it may also be more helpful to address the biological question in such studies.In our study, in order to investigate the contribution of sequence conservation in binding sites prediction and to make up the insufficiencies in purely geometry based methods, a simple yet efficient protein-binding sites prediction algorithm is presented, based on the geometry-based cavity identification integrated with sequence conservation information. Our method was compared with the other three classical tools: PocketPicker, SURFNET, and PASS, and evaluated on an existing comprehensive dataset of 210 non-redundant protein-ligand complexes. The results demonstrate that our approach correctly predicted the binding sites in 59% and 75% of cases among the TOP1 candidates and TOP3 candidates in the ranking list, respectively, which performs better than those of SURFNET and PASS, and achieves generally a slight better performance with PocketPicker.Our work has successfully indicated the importance of the sequence conservation information in binding sites prediction as well as provided a more accurate way for binding sites identification.
Co-reporter:Ruixin Zhu;Ming Xie;Fei Wang;Qi Liu;Tingguo Kang
Chinese Journal of Chemistry 2010 Volume 28( Issue 8) pp:1508-1509
Publication Date(Web):
DOI:10.1002/cjoc.201090257
Abstract
The arginine derivative Fmoc-Argω,ω′(Boc)2-OH has been prepared in perfect yield starting from Fmoc-Orn·HCl and N,N′-di-Boc-N′′-triflyguanidine with the presence of diisopropylethylamine (DIEA). This work provides an efficient and economical method for the preparation of this compound.
Co-reporter:Qi Liu;Dongsheng Che;Qi Huang;Zhiwei Cao
Chinese Journal of Chemistry 2010 Volume 28( Issue 9) pp:1587-1592
Publication Date(Web):
DOI:10.1002/cjoc.201090269
Abstract
The multi-target quantitative structure-activity relationship (QSAR) study of human immunodeficiency virus (HIV-1) inhibitors was addressed by applying a simple, yet effective linear regression model based on the multi-task learning paradigm. QSAR studies were performed on three datasets of HIV-1 inhibitors targeted on protease, integrase and reverse transcriptase, respectively. By using the multi-task learning method, the synergy among different set of inhibitors was exploited and an efficient multi-target QSAR modeling for HIV-1 inhibitors was obtained. The general descriptor features and drug-like features for compound description were ranked according to their jointly importance in multi-target QSAR modeling, respectively. A SAReport for investigating the relationships between compound structures and binding affinities was presented based on our multiple target analysis, which is expected to provide useful clues for the design of novel multi-target HIV-1 inhibitors with increasing likelihood of successful therapies.
Co-reporter:Jun Gao, Qi Huang, Dingfeng Wu, Qingchen Zhang, Yida Zhang, Tian Chen, Qi Liu, Ruixin Zhu, Zhiwei Cao, Yuan He
Gene (10 April 2013) Volume 518(Issue 1) pp:124-131
Publication Date(Web):10 April 2013
DOI:10.1016/j.gene.2012.11.061
G protein-coupled receptors (GPCRs) are the most frequently addressed drug targets in the pharmaceutical industry. However, achieving highly safety and efficacy in designing of GPCR drugs is quite challenging since their primary amino acid sequences show fairly high homology. Systematic study on the interaction spectra of inhibitors with multiple human GPCRs will shed light on how to design the inhibitors for different diseases which are related to GPCRs. To reach this goal, several proteochemometric models were constructed based on different combinations of two protein descriptors, two ligand descriptors and one ligand–receptor cross-term by two kinds of statistical learning techniques.Our results show that support vector regression (SVR) performs better than Gaussian processes (GP) for most combinations of descriptors. The transmembrane (TM) identity descriptors have more powerful ability than the z-scale descriptors in the characterization of GPCRs. Furthermore, the performance of our PCM models was not improved by introducing the cross-terms. Finally, based on the TM Identity descriptors and 28-dimensional drug-like index, two best PCM models with GP and SVR (GP-S-DLI: R2 = 0.9345, Q2test = 0.7441; SVR-S-DLI: R2 = 1.0000, Q2test = 0.7423) were derived respectively. The area of ROC curve was 0.8940 when an external test set was used, which indicates that our PCM model obtained a powerful capability for predicting new interactions between GPCRs and ligands.Our results indicate that the derived best model has a high predictive ability for human GPCR–inhibitor interactions. It can be potentially used to discover novel multi-target or specific inhibitors of GPCRs with higher efficacy and fewer side effects.Highlights► The interactions of inhibitors with multiple GPCRs were systematically studied. ► Different combinations of methods and descriptors were discussed. ► A model to design novel multi-target or specific inhibitors of GPCRs was derived.



















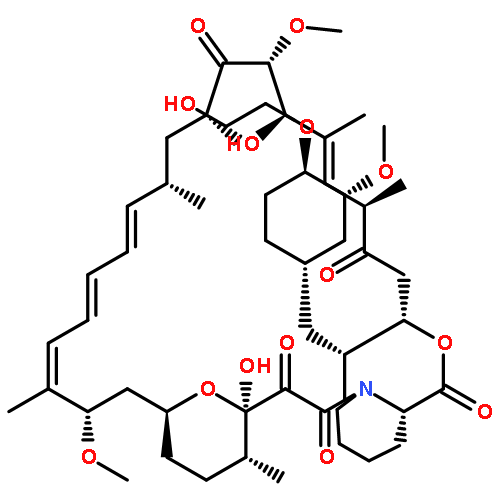
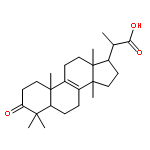
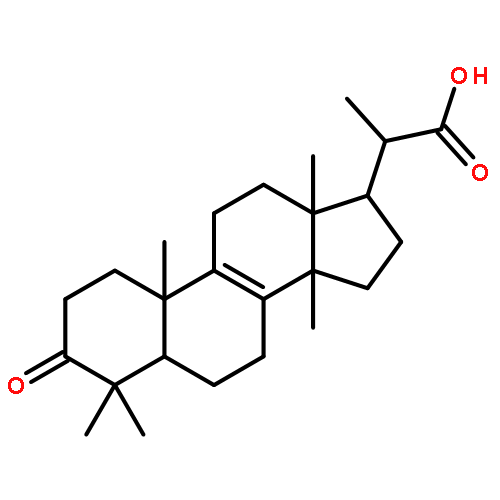
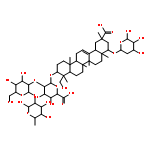
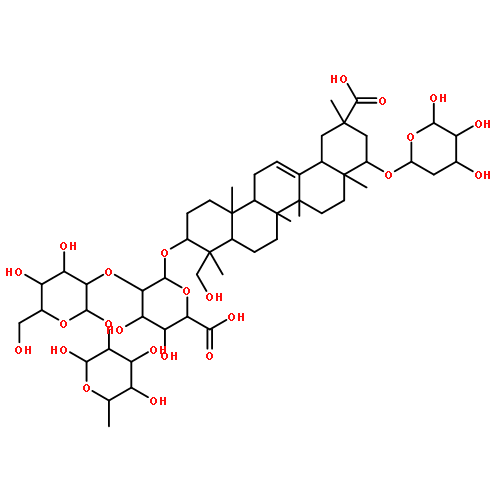
![b-D-Glucopyranosiduronic acid, (3b,4b,20a,22b)-20-carboxy-22-[(2-O-b-D-glucopyranosyl-a-L-arabinopyranosyl)oxy]-23-hydroxy-30-norolean-12-en-3-ylO-6-deoxy-a-L-mannopyranosyl-(1®2)-O-b-D-galactopyranosyl-(1®2)- (9CI)](http://img.cochemist.com/ccimg/147700/147666-63-5.png)
![b-D-Glucopyranosiduronic acid, (3b,4b,20a,22b)-20-carboxy-22-[(2-O-b-D-glucopyranosyl-a-L-arabinopyranosyl)oxy]-23-hydroxy-30-norolean-12-en-3-ylO-6-deoxy-a-L-mannopyranosyl-(1®2)-O-b-D-galactopyranosyl-(1®2)- (9CI)](http://img.cochemist.com/ccimg/147700/147666-63-5_b.png)


![1H-Benzimidazole,5-(difluoromethoxy)-2-[(R)-[(3,4-dimethoxy-2-pyridinyl)methyl]sulfinyl]-](http://img.cochemist.com/ccimg/142800/142706-18-1.png)
![1H-Benzimidazole,5-(difluoromethoxy)-2-[(R)-[(3,4-dimethoxy-2-pyridinyl)methyl]sulfinyl]-](http://img.cochemist.com/ccimg/142800/142706-18-1_b.png)
![1H-Benzimidazole,5-(difluoromethoxy)-2-[(S)-[(3,4-dimethoxy-2-pyridinyl)methyl]sulfinyl]-](http://img.cochemist.com/ccimg/142700/142678-35-1.png)
![1H-Benzimidazole,5-(difluoromethoxy)-2-[(S)-[(3,4-dimethoxy-2-pyridinyl)methyl]sulfinyl]-](http://img.cochemist.com/ccimg/142700/142678-35-1_b.png)
![(R)-5-Methoxy-2-(((4-methoxy-3,5-dimethylpyridin-2-yl)methyl)sulfinyl)-1H-benzo[d]imidazole](http://img.cochemist.com/ccimg/119200/119141-89-8.png)
![(R)-5-Methoxy-2-(((4-methoxy-3,5-dimethylpyridin-2-yl)methyl)sulfinyl)-1H-benzo[d]imidazole](http://img.cochemist.com/ccimg/119200/119141-89-8_b.png)